昨天做了一些前處理,
今天把昨天的處理好的資料做整合
首先是宜蘭縣鐵道(polyline)1
2
3import geopandas as gpd
rail_yilan=gpd.read_file('output/Rail_yilan.shp',encoding='utf-8')
rail_yilan
匯入車站資料,並進一步篩選通話中的車站
1 | station=gpd.read_file('output/station.shp',encoding='utf-8') |
最後的是對話資料1
2
3
4import pandas as pd
talk=pd.read_csv('output/talk.csv',encoding='utf-8')
talk['time']=[row['time'][:-2]+"00" for idx,row in talk.iterrows()]
talk
接下來,我們把原始的路線資料切成通訊對話逐字稿的模式,這裡會用到graph的資訊計算,
- 把polyline換算成graph
- 分別把車站設為起終點,計算路徑
- 例如在graph輸入宜蘭最近的node及羅東站最近的node,計算的得到這兩個站的路線
會採用這樣的做法是臨時決定的>.< 說不定改天有更好的做法
細節今天就先跳過,過幾天會講到,反正最終結果是要把polyline變成像是
福隆-貢寮 或是 宜蘭-二結的這種模式的線
1 | ## 這邊先手動整理對照表(對照上表) |
以下是我們要的路線整合結果: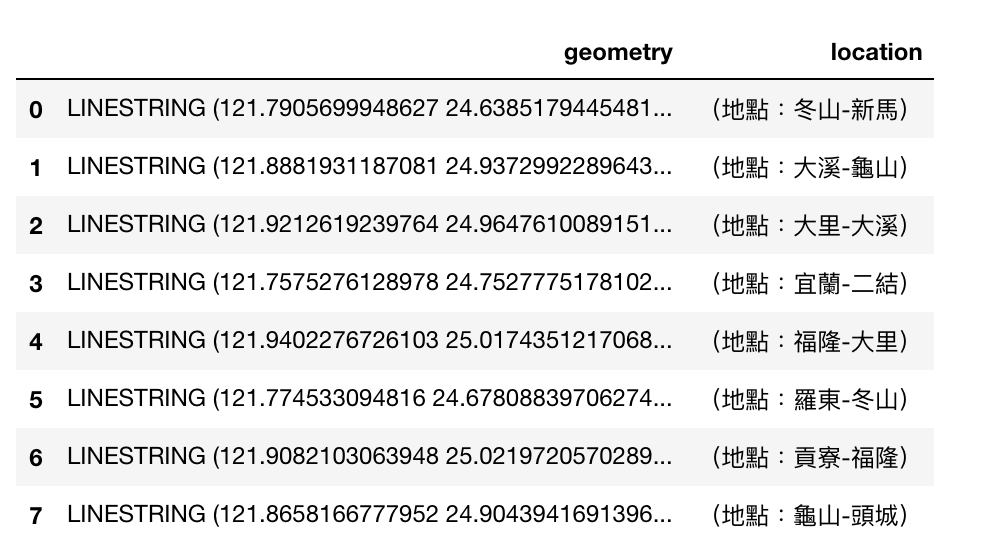
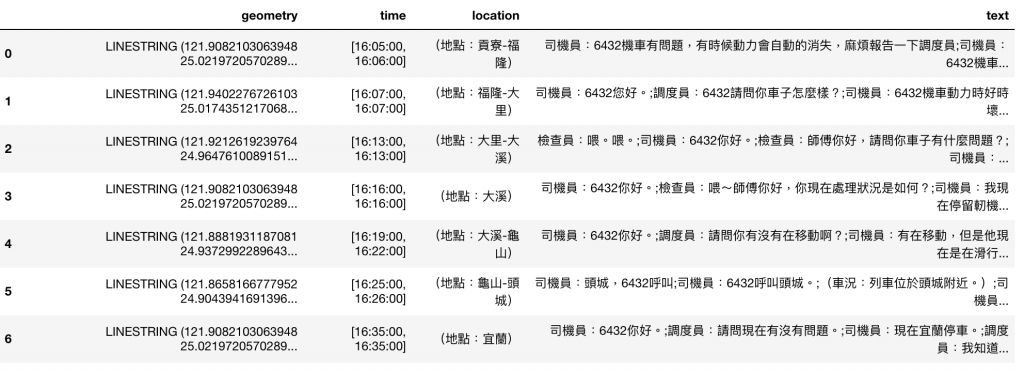
最後整合對話與路線,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 初始化
talk['geometry']=talk['location']
for i1,r1 in talk.iterrows():
for i2,r2 in train_lines.iterrows():
if r1['location']==r2['location']:
talk.at[i1,'geometry']=r2['geometry']
break
else:
talk.at[i1,'geometry']=talk.at[0,'geometry']
st=talk.at[0,'time']
temp_text=""
geoms=[]
temp_location=talk.at[0,'location']
for i1,r1 in talk.iterrows():
if temp_location!=talk.at[i1,'location']:
geoms.append([talk.at[i1-1,'geometry'],[st,talk.at[i1-1,'time']],talk.at[i1-1,'location'],temp_text])
##release
temp_location=talk.at[i1,'location']
temp_text=""
st=talk.at[i1,'time']
else:
temp_text+=talk.at[i1,'content']+";"
geoms.append([talk.at[i1,'geometry'],[st,talk.at[i1,'time']],talk.at[i1,'location'],temp_text])
train_lines_talk= gpd.GeoDataFrame(geoms)
train_lines_talk.columns=['geometry','time','location','text']
train_lines_talk
最終成果: